This post will provide an overview of how the Mulesoft Microsoft CRM Dynamics connector leverages Microsoft CRM Dynamics API and the ramifications of pulling large data sets via the Mulesoft Connector.
Mulesoft Microsoft Dynamics CRM Connector Overview
The Mulesoft connector supports DataSense Queries, Native Queries (FetchXML), setting the fetch size, and returning specific pages.
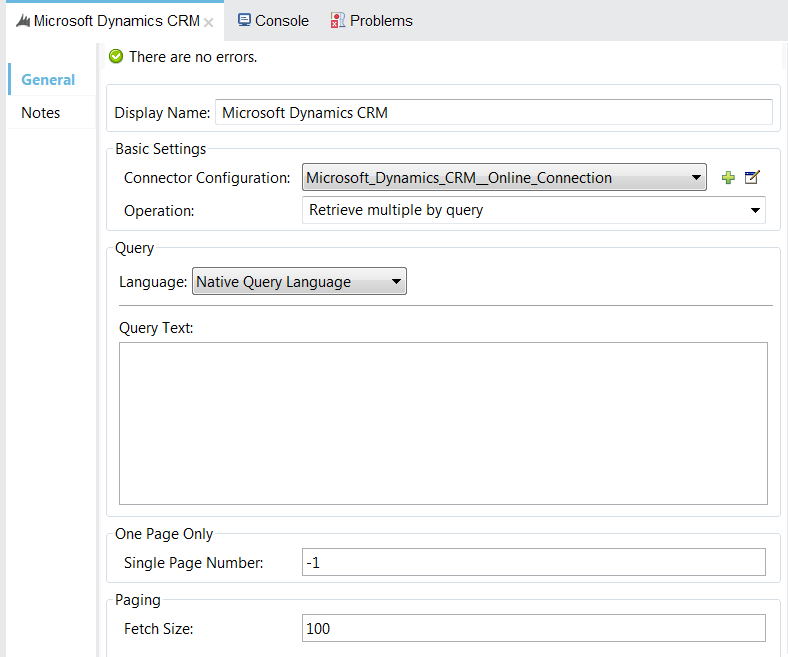
DataSense or Native Queries
For retrieving large datasets, use the Native Query Language (FetchXML), as Mulesoft will cache metadata by default if you use DataSense queries. This can run your Mulesoft JVM out of memory with even small calls.
Setting the Fetch Size
Controlling the fetch size is important and can impact your performance of requesting data from CRM. When pulling large datasets, it is best to run small performance tests to select the best size, which can range from one to 5,000.
Returning Specific Pages
The Mulesoft Connector also allows you to requests a certain page from CRM. However, our local testing has shown if the page request is over 10,000 records CRM will return an error stating the paging cookie is missing. This may be a bug, and a case has been submitted to Mulesoft for research.
Microsoft Dynamics Details
Microsoft Dynamics can take minutes to return pages of over 1,000 records.
How to Query Microsoft CRM Dynamics for Large Datasets
Option 1: Mulesoft Batch
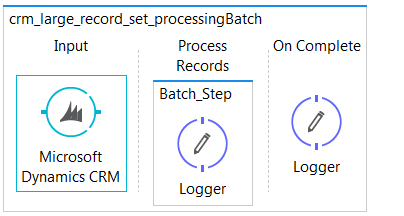
Pros
- All records are stored into the Mulesoft object store queue, so processing can start again if the engine fails.
Cons
- All records must be pulled down from CRM and loaded into the Mulesoft object store queue. This requires parsing the XML and creating records to be stored, which will flush to disk for large datasets.
Option 2: Asynch Mulesoft Batch
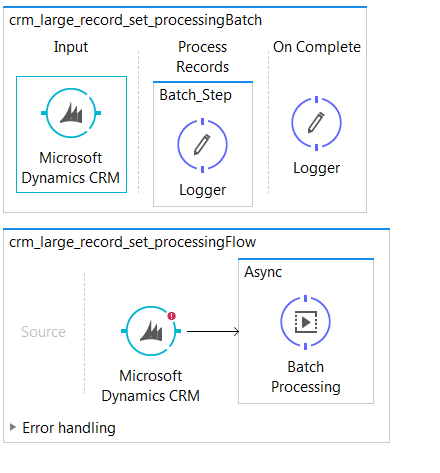
This option has no difference from Option 1 in how Mulesoft processes the record set from CRM.
Option 3: For Each
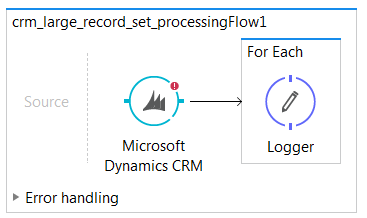
Pros
- Records will begin to process when a page is returned. This will speed up processing over using the batch since you are skipping the step of writing it to the Mulesoft object store.
Cons
- Not able to begin processing where left off if the engine fails during processing.
- The Mulesoft connector will not make the request for the next page until all the records have been processed from the page.
Option 4: Asynch for Each
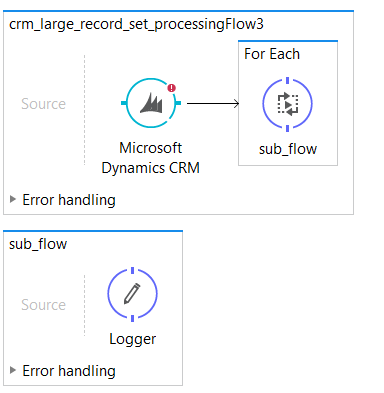
This option has the same behavior as Option 3
Option 5: Parallel For Each or Mulesoft Batches
This option will require the fetchXML to have a distinct clause that will not have overlapping records.
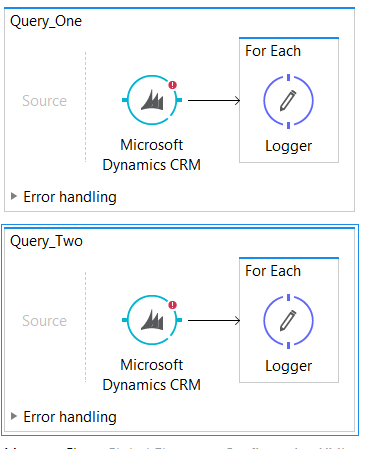
Pros
- Running multiple requests to CRM this way will limit the time spent waiting for pages to finish processing.
- This approach can be done with batch or for each, depending on requirements.
Cons
- Must understand your data in order to not have overlaps .

